MoBA Mixture of Block Attention for Long-Context LLMs
2025年2月18日,MoonShot 公布了论文 MoBA: Mixture of Block Attention for Long-Context LLMs。
MoBA (Mixture of Block Attention),这是一种将专家混合 (MoE) 原则应用于注意力机制的创新方法。这种新颖的架构在长上下文任务上表现出卓越的性能,同时提供了一个关键优势:能够在全注意力和稀疏注意力之间无缝转换,从而提高效率,而不会影响性能。
注意 MoBA是可训练的注意力机制
特点
可训练的区块稀疏注意力:完整的上下文被划分为多个区块,其中每个查询令牌都学习关注最相关的 KV 区块,从而实现长序列的高效处理。 无参数门控机制:引入了一种新颖的无参数 top-k 门控机制,为每个查询令牌选择最相关的区块,确保模型只关注信息量最大的区块。 在完全注意力和稀疏注意力之间无缝过渡:MoBA 旨在成为完全注意力的灵活替代品,允许在完全注意力模式和稀疏注意力模式之间无缝过渡。
扩展有效上下文长度对于将大型语言模型 (LLMs) 推进到通用人工智能 (AGI) 至关重要。然而,传统注意力机制中固有的计算复杂度的二次增长带来了令人望而却步的开销。现有的方法要么强加了强烈偏见的结构,例如特定于任务的 sink 或 window attention,要么从根本上将注意力机制修改为线性近似,其在复杂推理任务中的表现仍未得到充分探索。在这项工作中,MoonshotAI 提出了一种遵循 “less structure” 原则的解决方案,允许模型自主确定参加哪里,而不是引入预定义的偏差。块注意力混合 (MoBA),这是一种将专家混合 (MoE) 原则应用于注意力机制的创新方法。这种新颖的架构在长上下文任务上表现出卓越的性能,同时提供了一个关键优势:能够在全注意力和稀疏注意力之间无缝转换,从而提高效率,而不会影响性能。代码可在 MoonshotAI/MoBA 上获得。
MoBA 的一个运行示例: 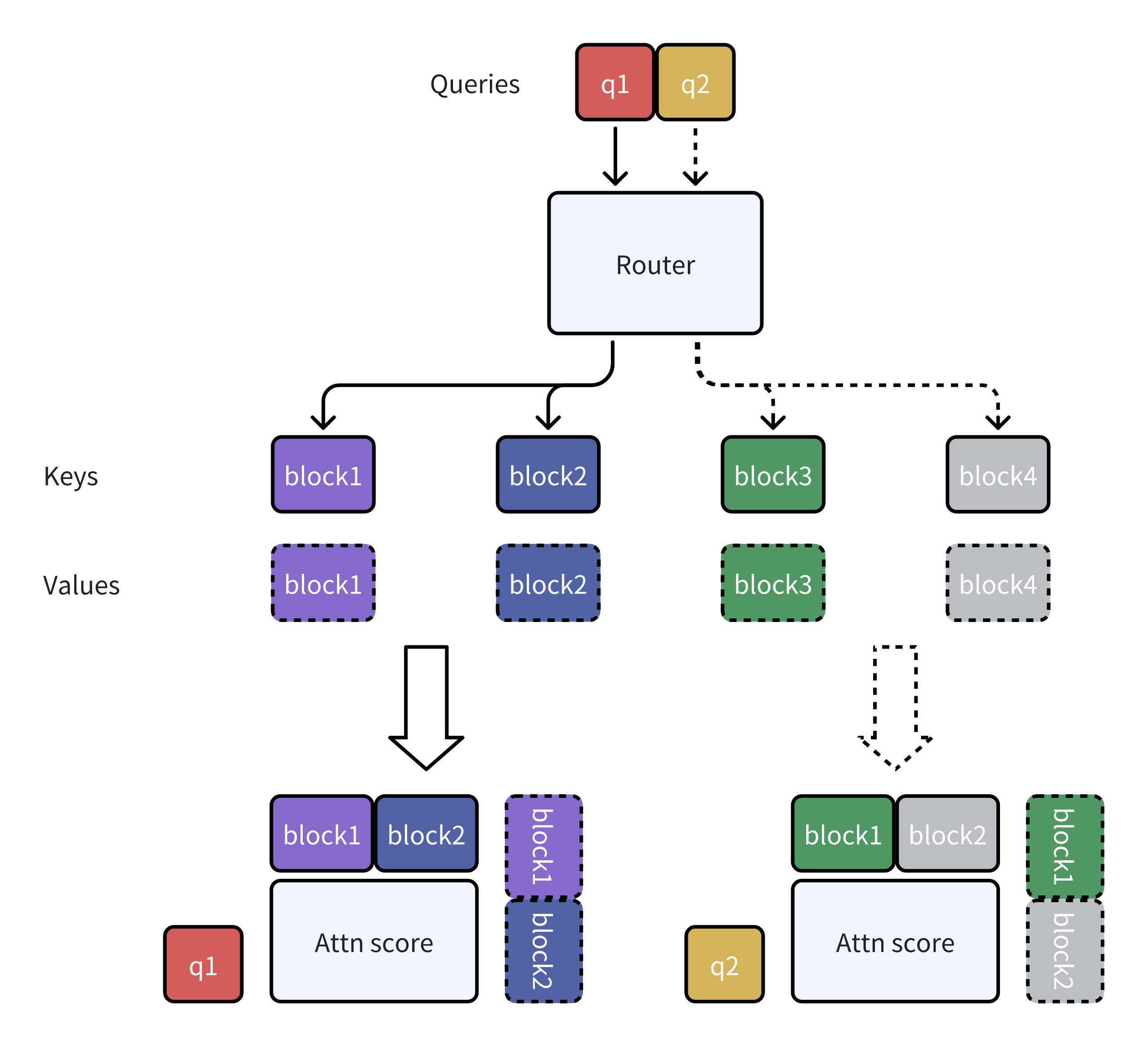
将 MoBA 集成到 Flash Attention 中: 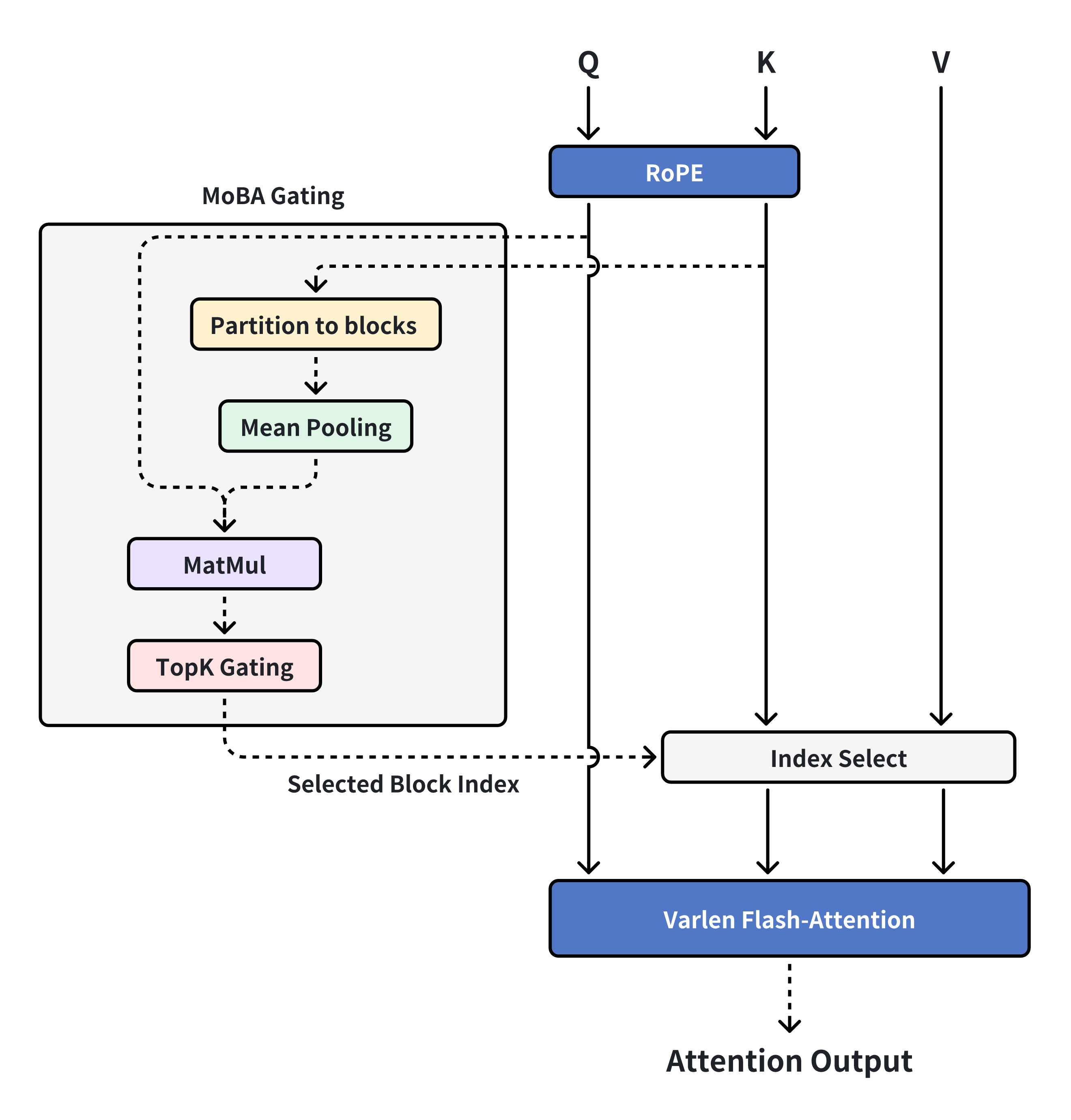
性能
与Flash Attention相比,MoBA在长上下文长度上表现更好。
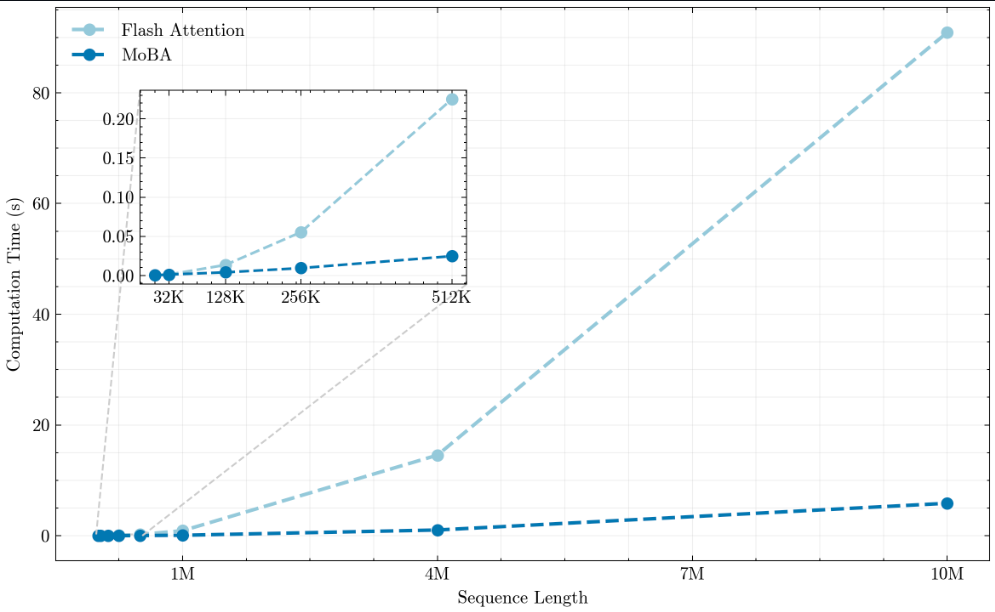
使用 1M 上下文长度进行评估结果如下:
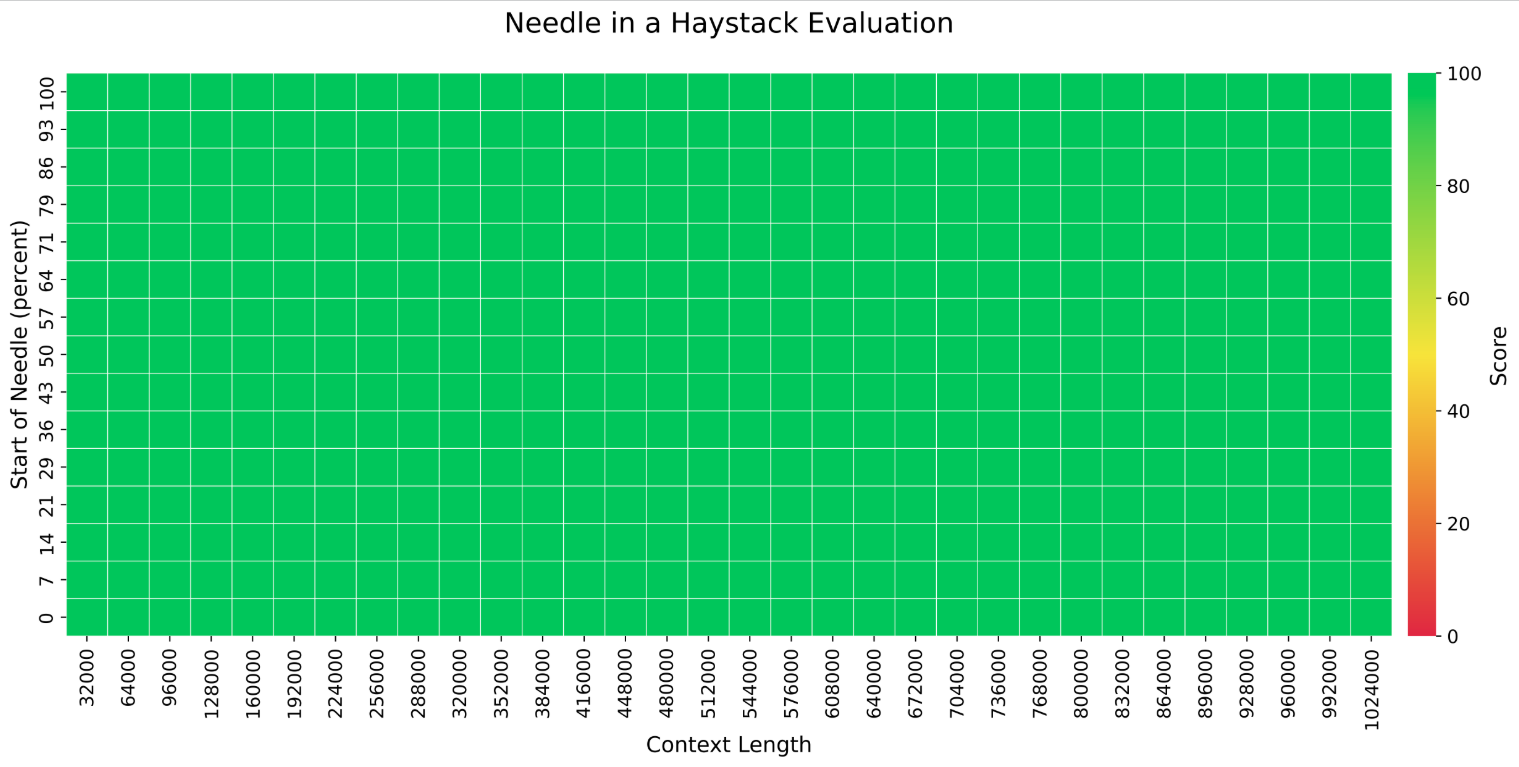
介绍
长上下文对通用人工智能 (AGI)的实现至关重要。在LLMs扩展序列长度 并非易事,因为与原版注意力机制相关的计算复杂度呈二次增长。这一挑战激发了一波研究浪潮,旨在在不牺牲性能的情况下提高效率。一个突出的方向利用了注意力分数固有的稀疏性。这种稀疏性既来自数学上——来自 softmax,其中研究了各种稀疏注意力模式。也来自生物学上,在与内存存储相关的大脑区域观察到稀疏连接。
现有的方法通常利用预定义的结构约束,来利用这种稀疏性。虽然这些方法可能很有效,但它们往往是高度特定于任务的,这可能会阻碍模型的整体泛化性。
一系列动态稀疏注意力机制,在推理时选择标记的子集。尽管这些方法可以减少长序列的计算量,但它们并没有大大减轻长上下文模型的密集训练成本,这使得有效地扩展到LLMs数百万个令牌的上下文变得具有挑战性。
另一种有前途的替代方法,即线性注意力模型。这些方法用线性近似取代了基于 softmax 的规范注意力,从而减少了长序列处理的计算开销。然而,由于线性和传统注意力之间的巨大差异,适应现有的 Transformer 模型通常会产生高转换成本。或者需要从头开始训练全新的模型。更重要的是,它们在复杂推理任务中的有效性证据仍然有限。
因此,一个关键的研究问题出现了:我们如何设计一个健壮且适应性强的注意力架构,在保留原始 Transformer 框架的同时坚持 “少结构 ”的原则,让模型在不依赖预定义偏差的情况下确定在哪里参加? 理想情况下,这种架构将在完全注意力模式和稀疏注意力模式之间无缝转换,从而最大限度地提高与现有预训练模型的兼容性,并在不影响性能的情况下实现高效推理和加速训练。
因此,我们引入了块注意力混合 (MoBA),这是一种新颖的架构,它建立在专家混合 (MoE)的创新原则之上,并将其应用于 Transformer 模型的注意力机制。MoE 主要用于 Transformers 的前馈网络 (FFN) 层,但 MoBA 率先将其应用于长上下文注意,允许为每个查询令牌动态选择历史相关的键和值块。这种方法不仅提高了 的效率LLMs,而且还使它们能够处理更长、更复杂的提示,而不会成比例地增加资源消耗。MoBA 通过将上下文划分为多个块并采用门控机制选择性地将查询标记路由到最相关的块,解决了传统注意力机制的计算效率低下问题。这种块稀疏注意力显著降低了计算成本,为更高效地处理长序列铺平了道路。该模型能够动态选择信息量最大的键块,从而提高性能和效率,尤其适用于涉及大量上下文信息的任务。