Native Sparse Attention
2025年2月16日,DeepSeek 公布了论文 Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention。
NSA(Native Sparse Attention)是一种原生可训练的稀疏注意力机制,它运用创新算法与实现硬件对齐,以实现高效的长上下文建模。
注意 NSA是可训练的注意力机制
NSA 原理
NSA 采用动态分层稀疏策略,将粗粒度令牌压缩与细粒度令牌选择相结合,以保持全局上下文感知和局部精度。通过下面两项关键创新推进了稀疏注意力设计:
- 通过算术强度平衡算法设计实现了大幅加速,并针对现代硬件进行了优化。
- 支持端到端训练,在不牺牲模型性能的情况下减少训练计算。
NSA vs Full Attention
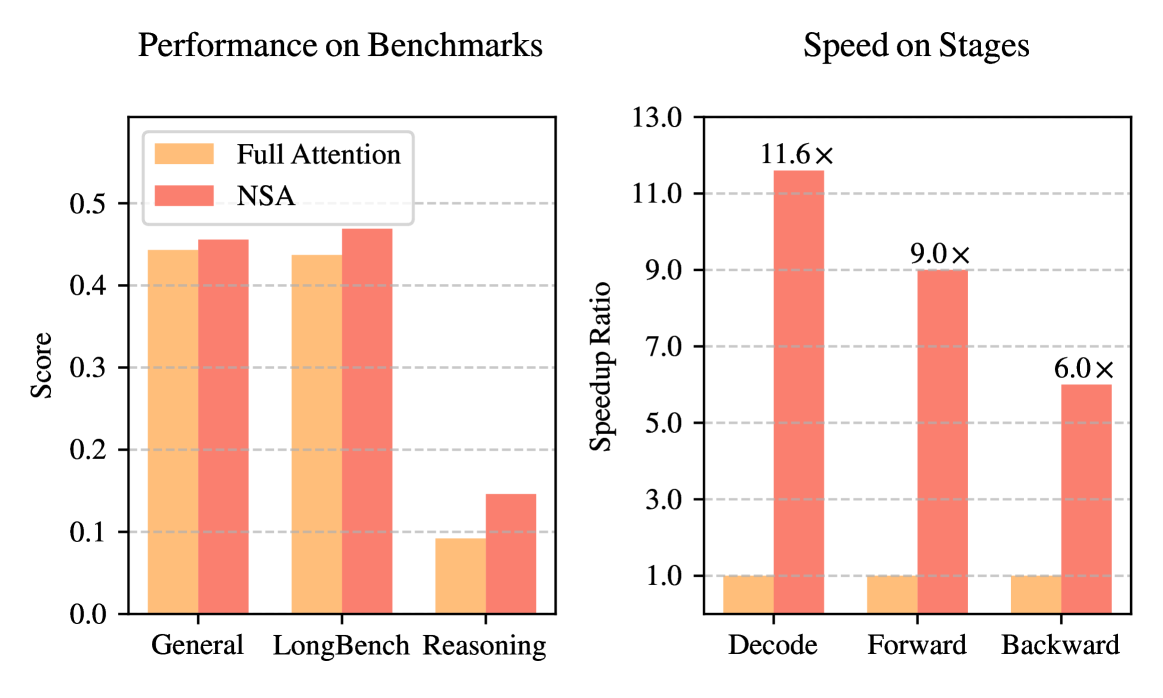
论文中 Full Attention 模型与 NSA 的性能和效率对比。
左:NSA尽管稀疏,但在一般基准、长期上下文任务和推理评估方面平均超过了Full Attention基线。
右:对于 64k 长度的序列处理,与 Full Attention 相比,NSA 在所有阶段(解码、前向传播和后向传播)都实现了显著的计算速度。
NSA架构概述
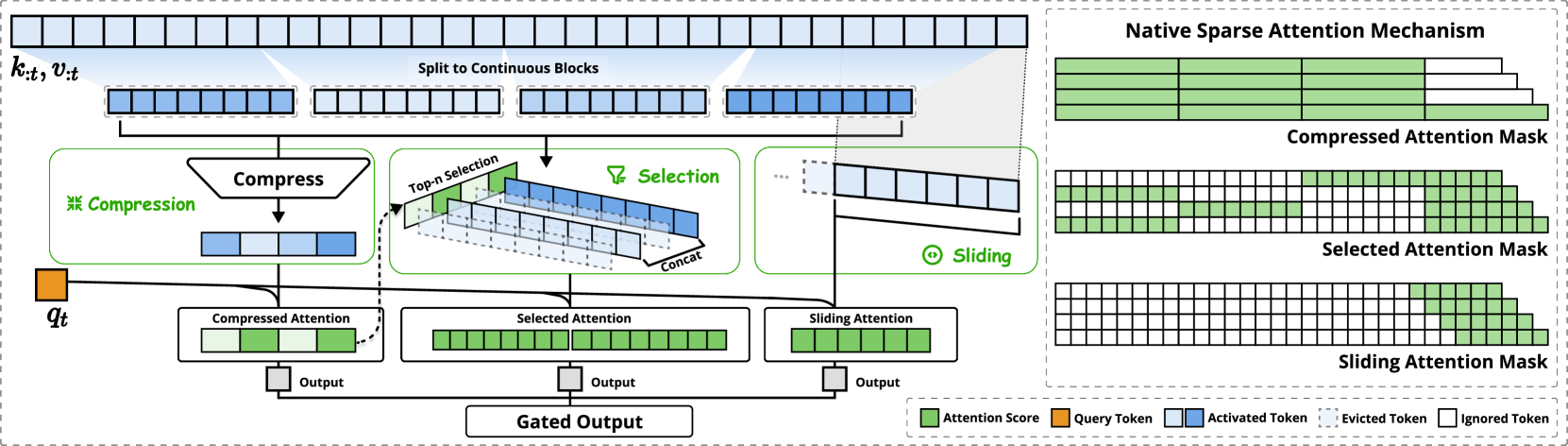
论文中NSA架构概述。
左:框架通过三个并行的注意力分支处理输入序列:对于给定的查询,前面的键和值被处理为粗粒度模式的压缩注意力、重要标记块的选定注意力和本地上下文的滑动注意力。
右:每个分支产生的不同注意力模式的可视化。绿色区域表示需要计算注意力分数的区域,而白色区域表示可以跳过的区域。
现有的稀疏注意力问题
许多现有的稀疏注意力方法专注于减少 KV 缓存或理论计算减少,但难以在高级框架或后端中实现显著的延迟减少。NSA将高级架构和硬件高效实现相结合的算法,以充分利用稀疏性来提高模型效率。
现有的稀疏注意力方法主要针对推理,而训练中的计算挑战在很大程度上没有得到解决。这种限制阻碍了通过高效训练开发功能更强大的长上下文模型。
现有的稀疏注意力用于训练也有如下挑战:
- 不可训练的组件。ClusterKV(包括 k-means 聚类)和 MagicPIG(包括基于 SimHash 的选择)等方法中的离散运算在计算图中造成了不连续性。这些不可训练的组件阻止了梯度流通过标记选择过程,从而限制了模型学习最佳稀疏模式的能力。
- 低效的反向传播。一些理论上可训练的稀疏注意力方法存在实践训练效率低下的问题。HashAttention 等方法中使用的令牌粒度选择策略,导致需要在注意力计算期间从 KV 缓存加载大量单独的令牌。这种非连续的内存访问阻止了对 FlashAttention 等快速注意技术的有效适应,这些技术依赖于连续的内存访问和分块计算来实现高吞吐量。因此,实施被迫回退到硬件利用率低,从而显著降低训练效率。
NSA 的算法设计和运算符实现
主要是如何实现NSA架构概述图中的三个并行注意力,token如何压缩,token如何选择,滑动窗口等,具体细节可以查看论文:Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention
NSA 的内核设计
为了在训练和预填充期间实现 FlashAttention 级别的加速,在 Triton 上实现了硬件对齐的稀疏注意力内核。鉴于 MHA 是内存密集型的,并且解码效率低下,于是专注于具有共享 KV 缓存的架构,如 GQA 和 MQA,遵循当前最先进的 LLMs。虽然压缩和滑动窗口注意力计算很容易与现有的 FlashAttention-2 内核兼容,但还是引入了用于稀疏选择注意力的专用内核设计。如果我们遵循 FlashNotice 的策略,将时间连续的查询块加载到 SRAM 中,这将导致内存访问效率低下,因为块内的查询可能需要不相交的 KV 块。为了解决这个问题,主要优化在于不同的查询分组策略:对于查询序列上的每个位置,我们将 GQA 组中的所有查询头(它们共享相同的稀疏 KV 块)加载到 SRAM 中。
NSA内核架构具有以下主要特性:
- 以组为中心的数据加载。对于每个内部循环,在 处加载组中的所有 heads 查询 及其共享的稀疏 key/value 块索引 。
- 共享 KV 获取。在内部循环中,按顺序加载索引的 连续键/值块到 SRAM 中,以 最小化内存加载,其中 内核块大小满足 。
- 网格上的外环。由于不同查询块的内部循环长度(与所选块数 n 成正比)几乎相同,因此我们将查询/输出循环放在 Triton 的网格调度器中,以简化和优化内核。
这种设计通过以下方式实现近乎最佳的算术强度:
- 通过分组共享消除冗余 KV 传输
- 在 GPU 流式多处理器之间平衡计算工作负载。
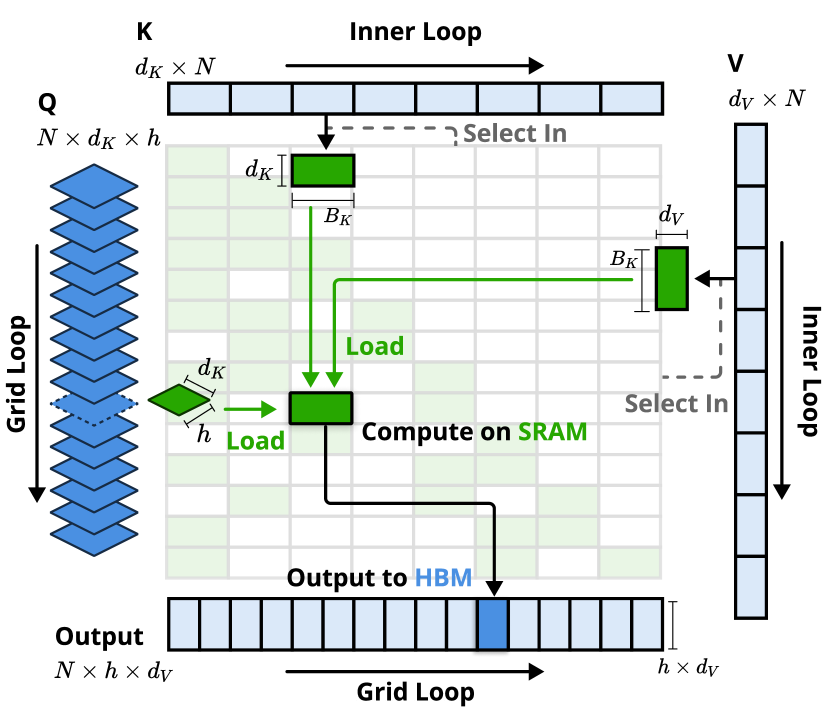
内核通过 GQA 组加载查询(网格循环),获取相应的稀疏 KV 块(Inner Loop),并在 SRAM 上执行注意力计算。绿色块表示 SRAM 上的数据,而蓝色块表示 HBM 上的数据。
性能
LongBench 基础测试
LLMTest_NeedleInAHaystack 检索能力测试
使用LLMTest_NeedleInAHaystack进行大海捞针检索能力测试
在 64k 上下文长度下,跨上下文位置的大海捞针检索准确性。NSA 通过其分层稀疏注意力设计实现了完美的准确性。
链式推理评估
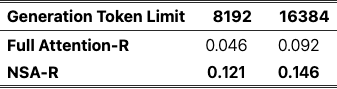
监督微调后的模型基于美国数学邀请考试 (AIME 24)的评估。NSA-R 在 8k 和 16k 序列长度上都表现出比 Full Attention-R 更好的性能。
效率
在 8-GPU A100 系统上评估了 NSA 与 Full Attention 的计算效率,如下:
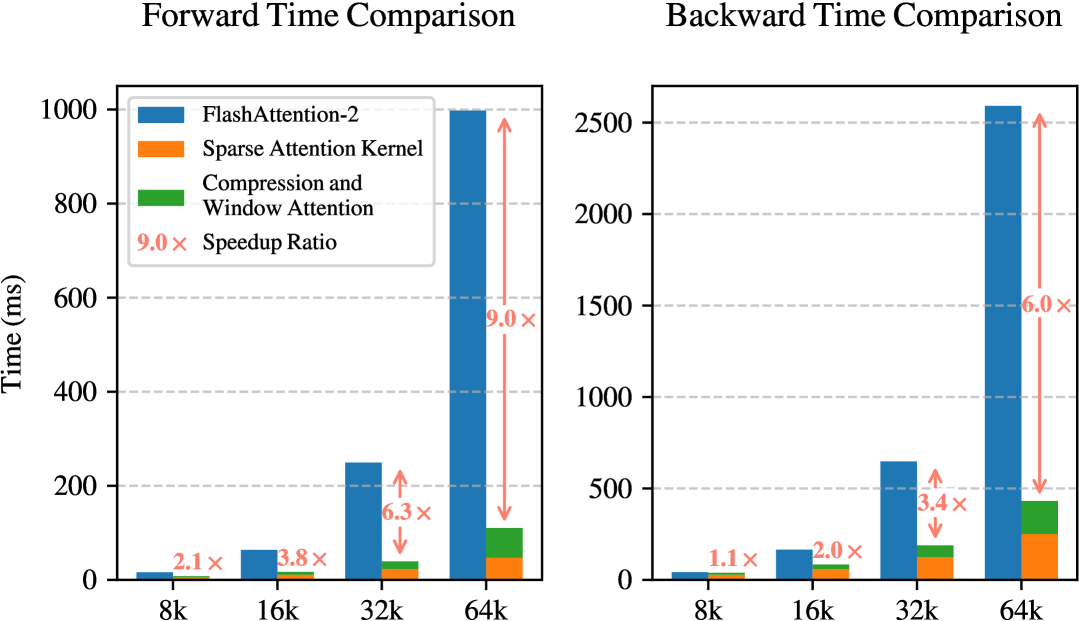
基于 Triton 的 NSA 内核与基于 Triton 的 FlashAttention-2 内核的比较。NSA显著减少了所有上下文长度的延迟,随着输入长度的增加,改进变得更加明显。
NSA vs FullAttention 训练速度对比:
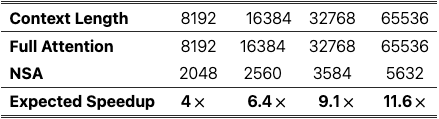
相同上下文长度,NSA 的训练速度比 Full Attention 快,预期的加速比与内存访问量大致呈线性关系。
由于 Attention 的解码速度主要由内存访问瓶颈决定,而内存访问瓶颈与 KV 缓存的加载量密切相关。如上图所示,随着解码长度的增加,我们的方法表现出延迟显着减少,最高可达 11.6 × 64K 上下文长度的加速。内存访问效率的这种优势也会随着序列的延长而放大。
总结
NSA 是一种硬件对齐的稀疏注意力架构,用于高效的长期上下文建模。通过在可训练架构中将分层令牌压缩与块式令牌选择集成,NSA 架构实现了加速训练和推理,同时保持了 Full Attention 性能。NSA 通过展示一般基准性能与 Full Attention 基线相匹配,超越长期上下文评估中的建模能力,以及增强的推理能力,所有这些都伴随着计算延迟的可衡量减少并实现显著的加速,从而推动了最先进的技术。
NSA 向我们展示了,在不牺牲性能的情况下,通过优化算法,可以用更低的成本以更高的效率训练模型。
参考
Native Sparse Attention: Hardware-Aligned and Natively Trainable Sparse Attention