AnythingLLM 接入RAG
使用AnythingLLM接入RAG,需要使用Ollama本地运行模型,nomic-embed-text作为嵌入模型。
安装Ollama
本地安装Ollama参考Ollama 使用
下载nomic-embed-text
nomic-embed-text是一个完全开源的文本嵌入模型,由Nomic团队发布。该模型的主要特点是其在处理短文和长文本任务方面超越了现有的模型,如OpenAI的Ada-002和text-embedding-3-small。nomic-embed-text的上下文长度为8192,参数数量为137M,这使得它在处理长文本时表现出色。
nomic-embed-text-v1.5是Nomic Embed的改进版本,利用了Matryoshka表示学习,允许在嵌入大小与性能之间灵活权衡。通过引入Matryoshka表示学习,该项目在提高嵌入质量的同时,提供了更大的嵌入尺寸和序列长度。
使用Ollama下载nomic-embed-text
$ ollama pull nomic-embed-text如果直接使用Ollama下载nomic-embed-text比较慢,可以选择使用ModelScope社区中的模型。具体使用参考Ollama加载ModelScope模型
我是直接下载的ModelScope中的模型
$ ollama pull modelscope.cn/Embedding-GGUF/nomic-embed-text-v1.5-GGUF
pulling manifest
pulling d4e388894e09... 100% ▕█████████████████████████████████████████████████████████████████████▏ 84 MB
pulling 885769ff7150... 100% ▕█████████████████████████████████████████████████████████████████████▏ 17 B
pulling c71d239df917... 100% ▕█████████████████████████████████████████████████████████████████████▏ 11 KB
pulling 8ad2be369ff9... 100% ▕█████████████████████████████████████████████████████████████████████▏ 205 B
verifying sha256 digest
writing manifest
success注意 有一点儿需要注意的是,默认下载的是Q4_K_M版的模型
AnythingLLM
AnythingLLM 是由 Mintplex Labs 开发的开源 AI 工具,可以将任何东西转换为您可以查询和聊天的训练有素的聊天机器人。AnythingLLM 是一款 BYOK(自带密钥)软件,因此除了您想使用的服务外,此软件不收取订阅费、费用或其他费用。
AnythingLLM 是将强大的 AI 产品(如 OpenAi、GPT-4、LangChain、PineconeDB、ChromaDB 等)整合在一个整洁的包中而无需繁琐操作的最简单方法,可以将您的生产力提高 100 倍。
AnythingLLM 可以完全在您的本地计算机上运行,几乎没有开销,您甚至不会注意到它的存在!无需 GPU。也可以进行云端和本地安装。 AI 工具生态系统每天都在变得更强大。AnythingLLM 使其易于使用。
下载AnythingLLM
进入AnythingLLM下载桌面版本。
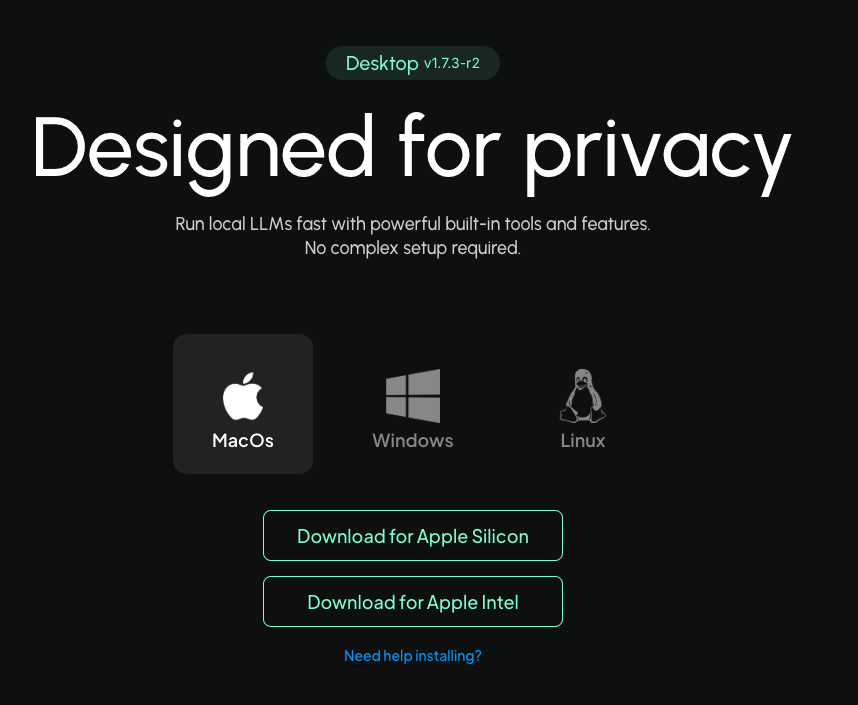
这里下载的是Mac+M1配置的版本,下载完成之后,直接安装。
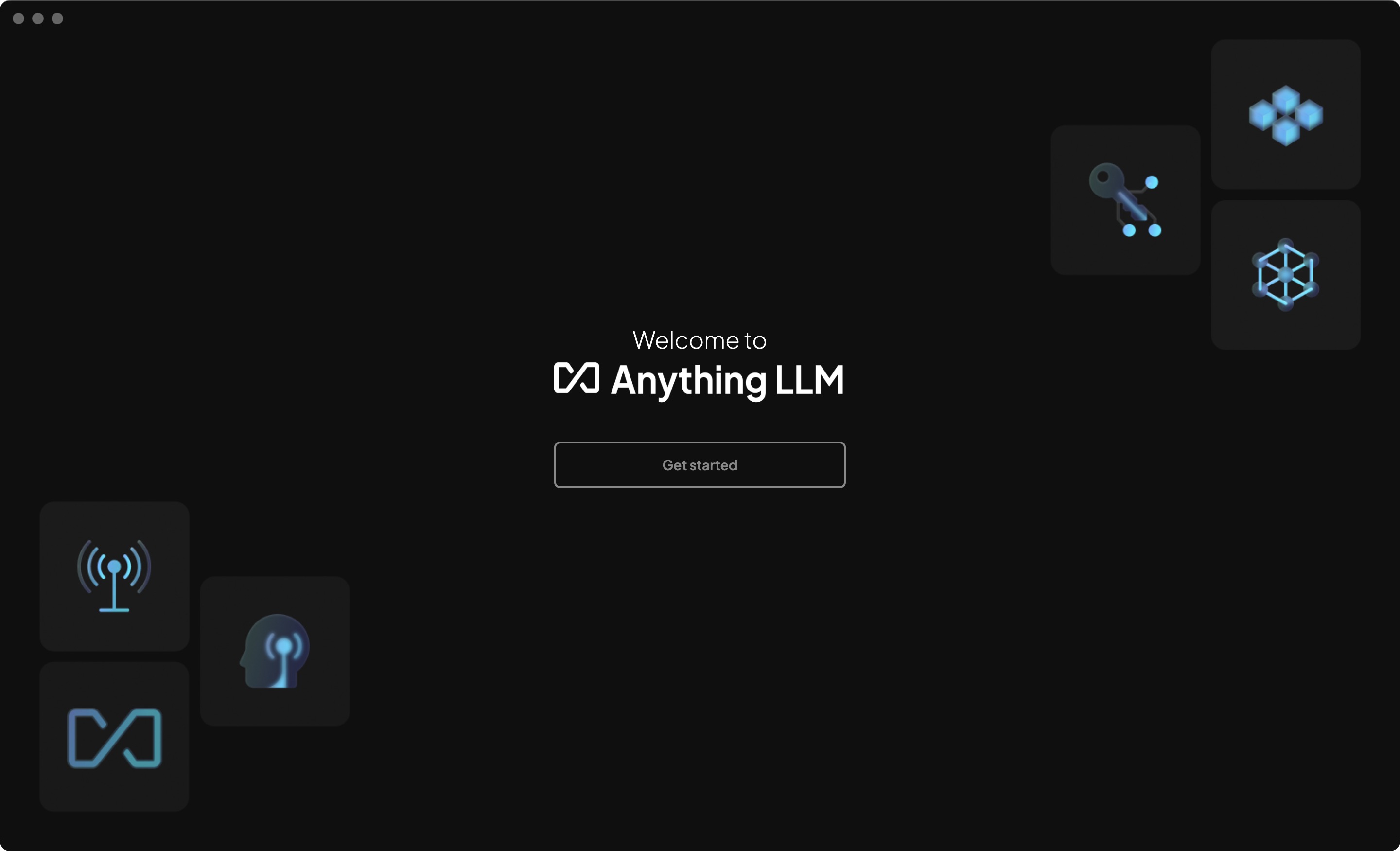
启动AnythingLLM
启动后,点击Get Started。
点击下一步
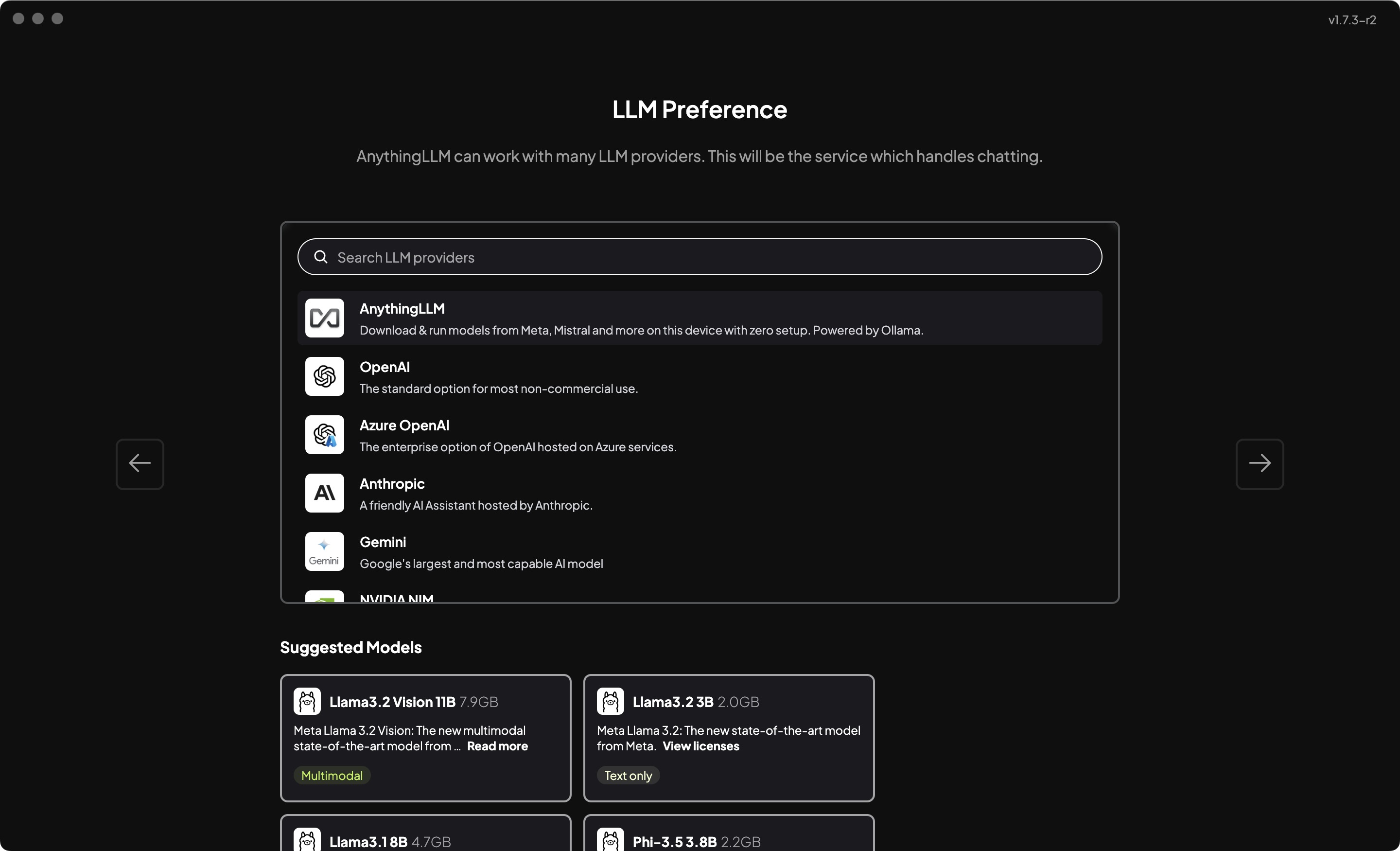
点击下一步
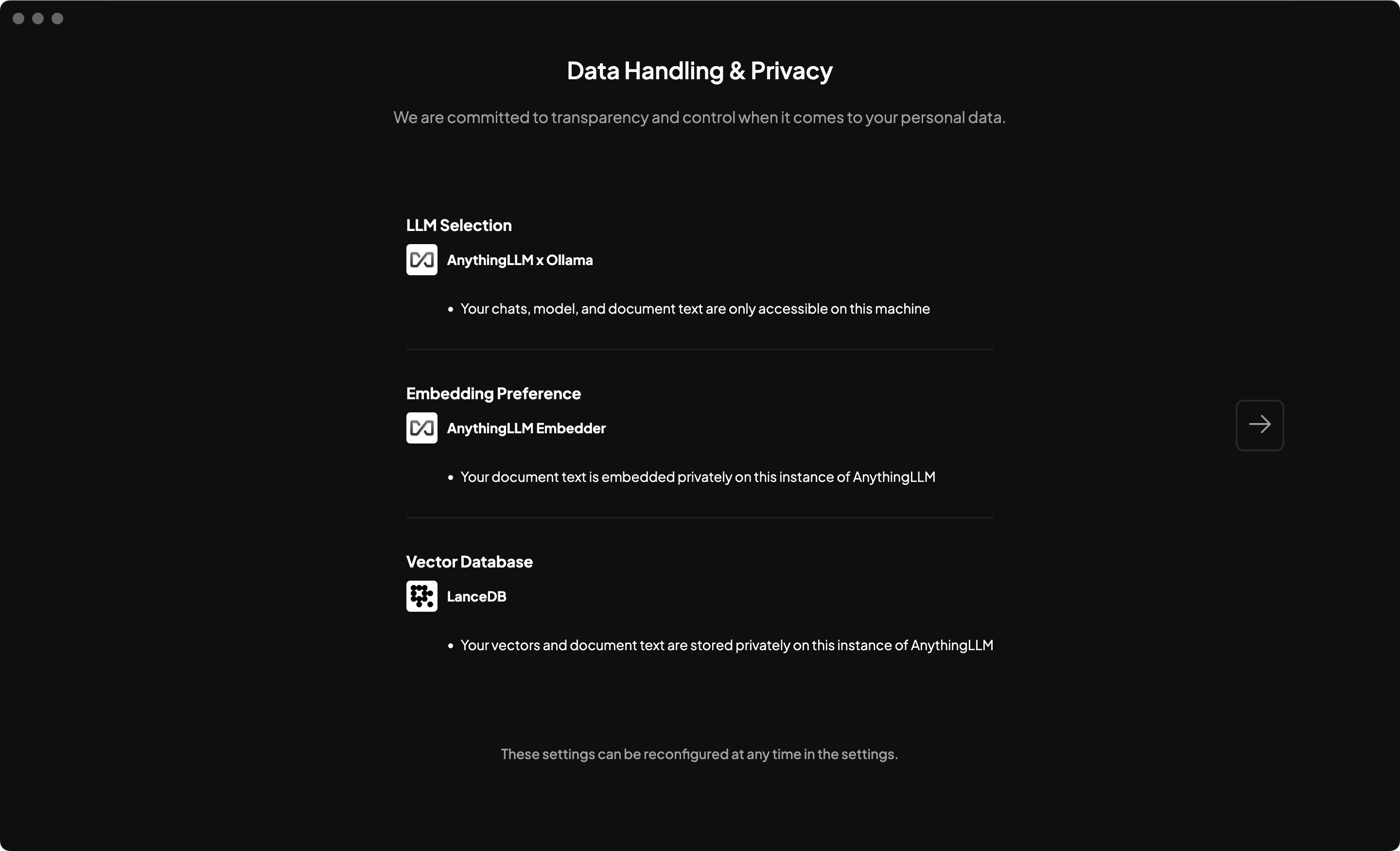
注册后,点击下一步
输入工作空间名称后,点击下一步
进入工作空间
设置
切换语言
如果需要切换语言为英文,可以点击右下角设置按钮,将Display Language选项,切换为Chinese即可。
设置模型
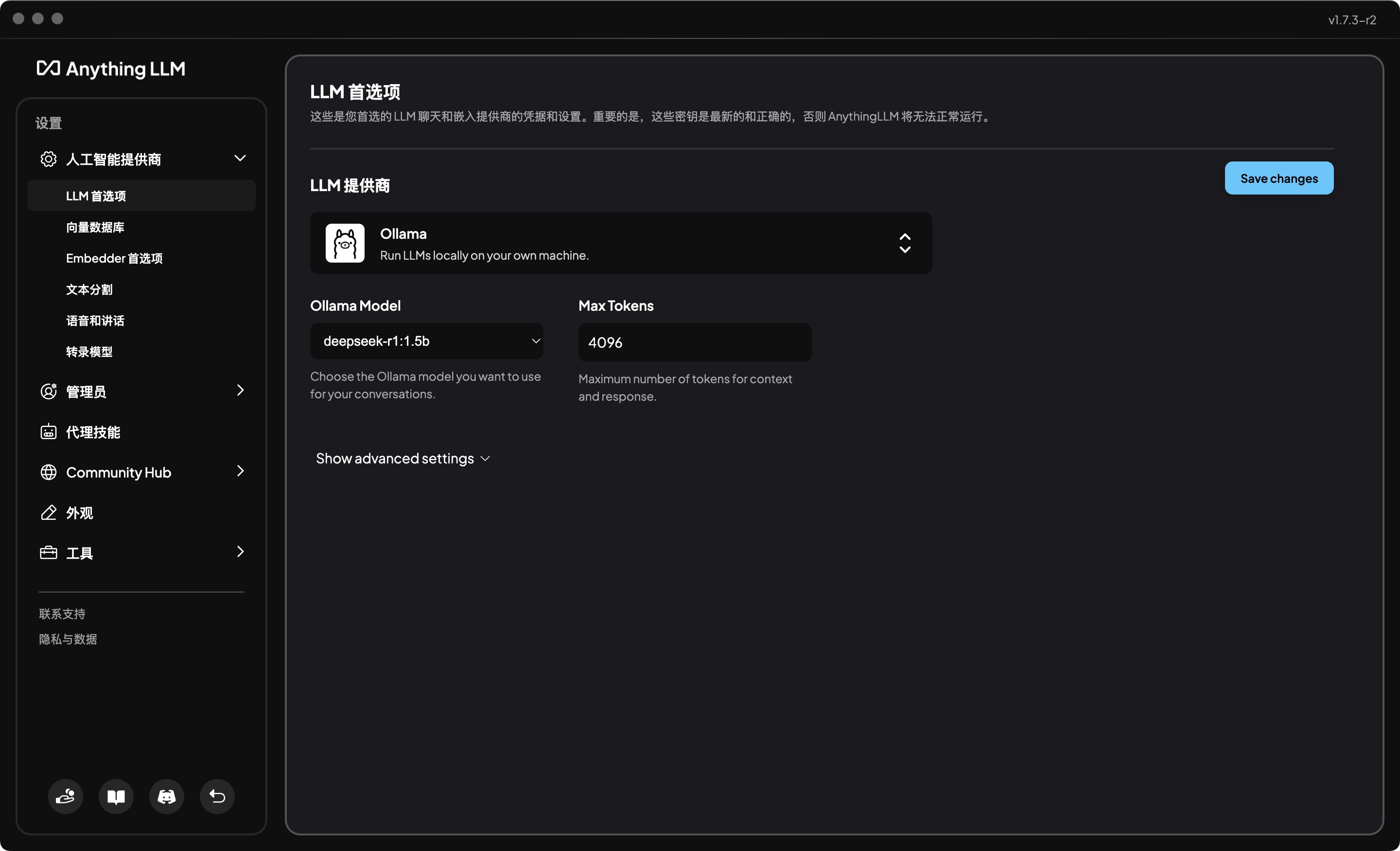
- 展开人工智能提供商
- 选择LLM首选项
- 选择LLM提供商为Ollama
- 选择Ollama模型为
deepseek-r1:1.5b,这根据自己的需要选择,Max Tokens保持默认的即可。 - 保存
设置Embedder
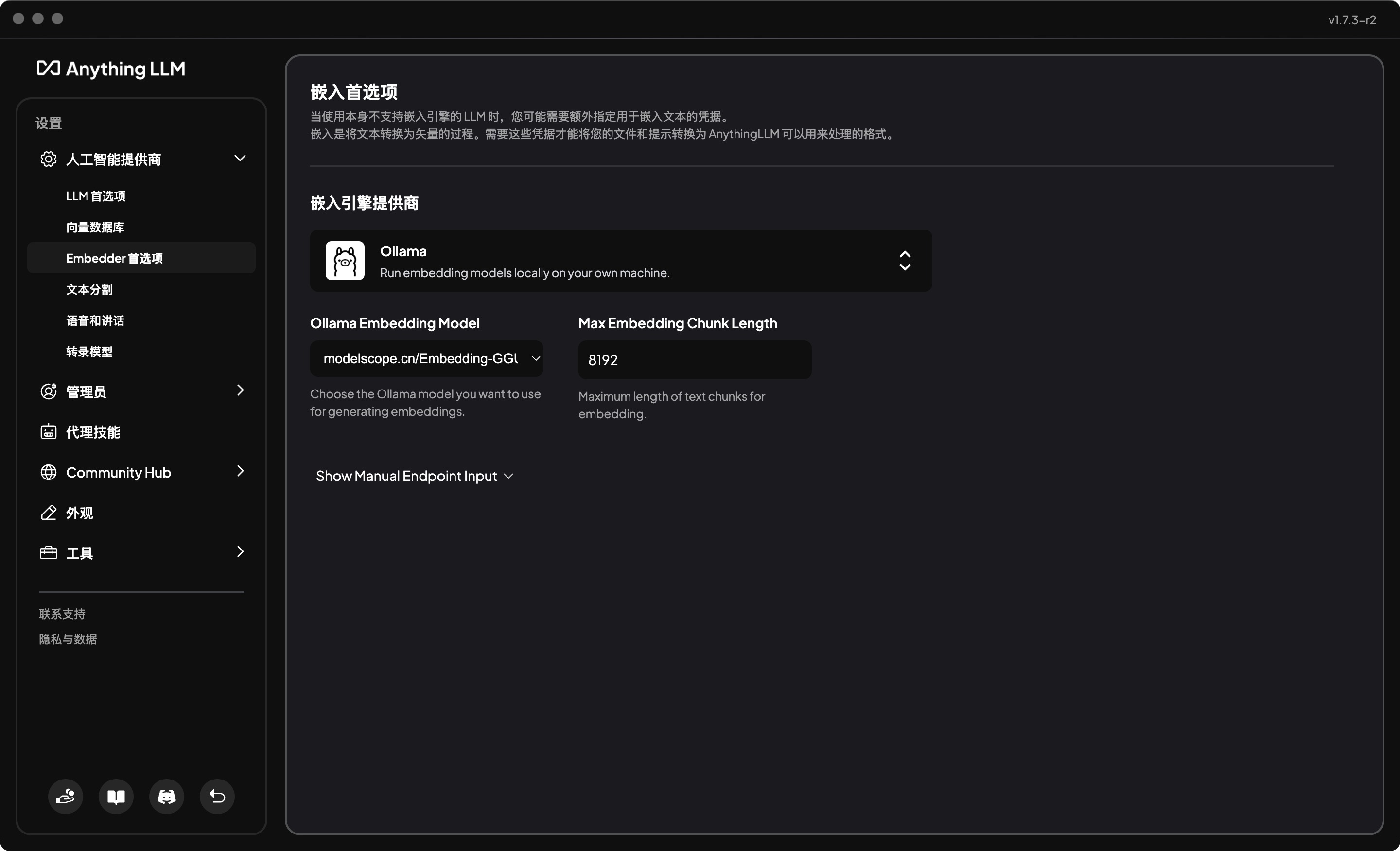
- 展开人工智能提供商
- 选择Embadder首选项
- 选择嵌入引擎提供商为Ollama
- 选择Ollama模型为
modelscope.cn/Embedding-GGUF/nomic-embed-text-v1.5-GGUF,这根据自己的需要选择,Max Embedding Chunk Length保持默认的即可。 - 保存
工作区聊天设置
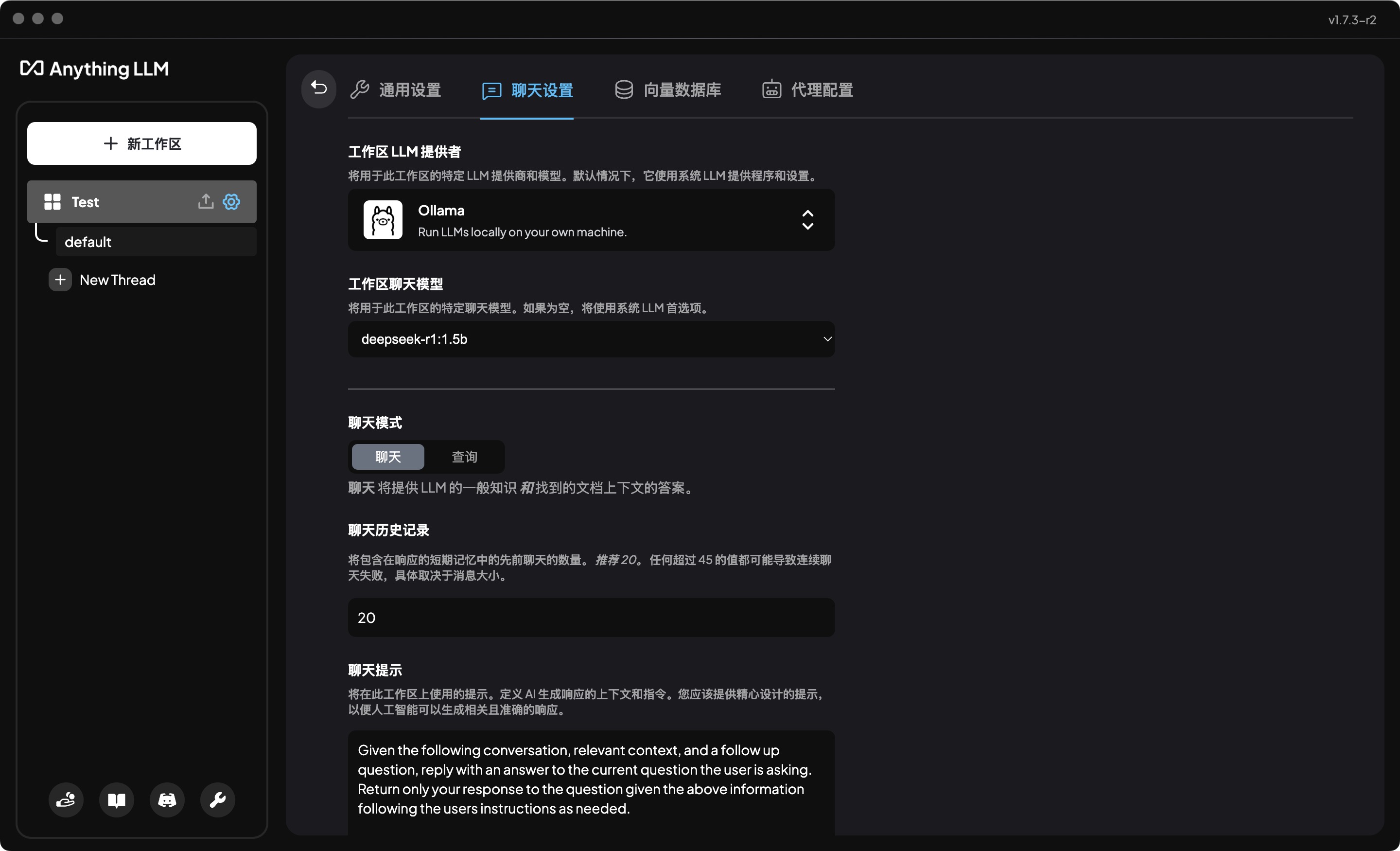
- 点击工作区名称右侧的设置按钮,
hover状态可见 - 选择“聊天设置”
- 工作区LLM提供商选择
Ollama - 工作区聊天模型选择
deepseek-r1:1.5b - 点击底部的
Update workspace agent更新
工作区代理配置
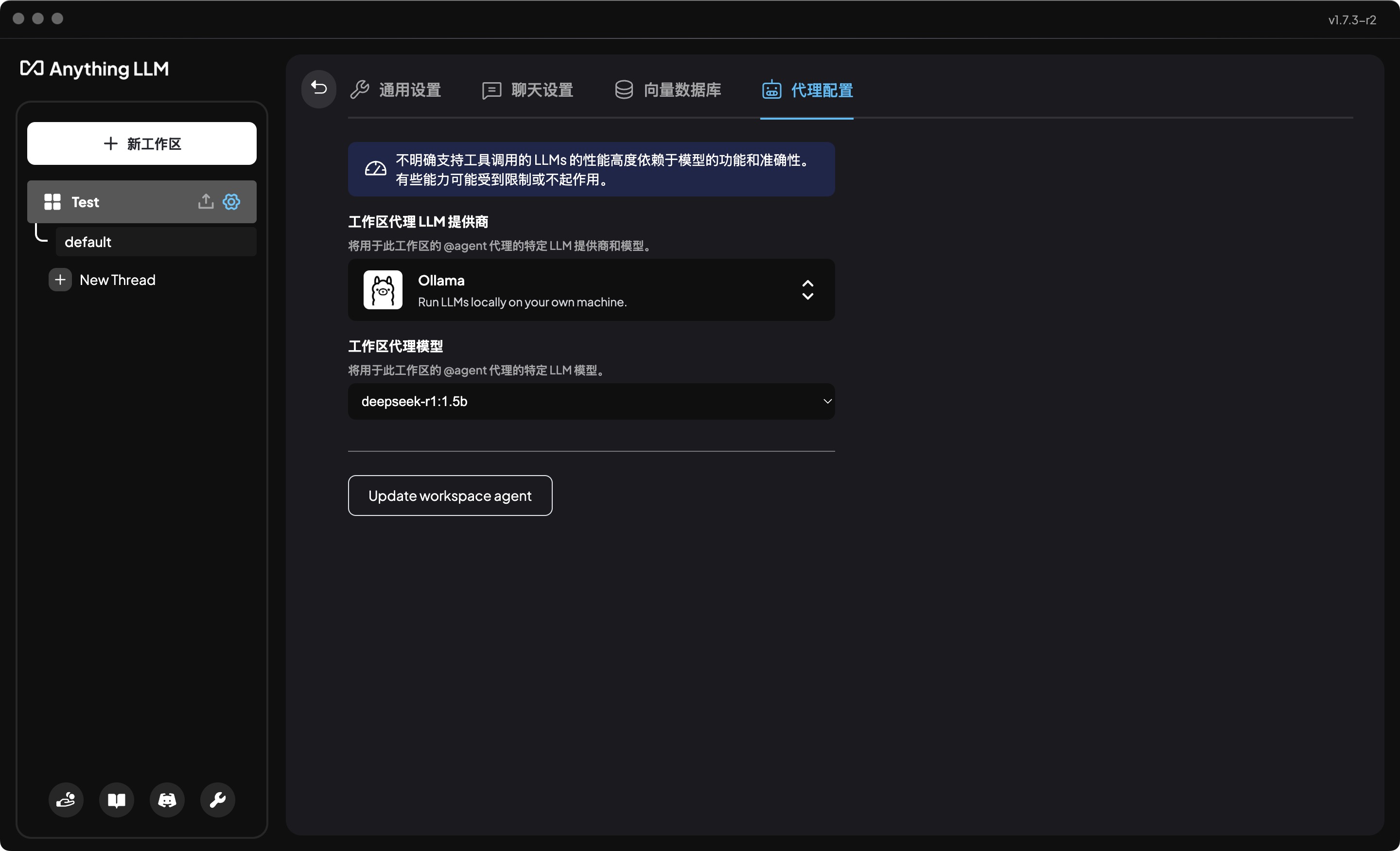
- 点击工作区名称右侧的设置按钮,
hover状态可见 - 选择“代理配置”
- 工作区LLM提供商选择
Ollama - 工作区代理模型选择
deepseek-r1:1.5b - 点击底部的
Update workspace agent更新
使用
在完成设置之后,我们就可以在工作空间中使用了。
$ ps aux | grep ollama | grep -v grep
matias 97824 0.0 0.1 412087456 20736 ?? S 五03下午 6:09.96 /Applications/Ollama.app/Contents/Resources/ollama serve
matias 91216 0.0 6.6 413790288 1114192 ?? S 11:22上午 0:02.22 /Applications/Ollama.app/Contents/Resources/ollama runner --model /Users/matias/.ollama/models/blobs/sha256-aabd4debf0c8f08881923f2c25fc0fdeed24435271c2b3e92c4af36704040dbc --ctx-size 8192 --batch-size 512 --n-gpu-layers 29 --threads 4 --mlock --parallel 4 --port 54831通过上面的查询可以看到,当我们使用时,会启动ollama的deepseek-r1:1.5b模型为我们提供服
投喂数据
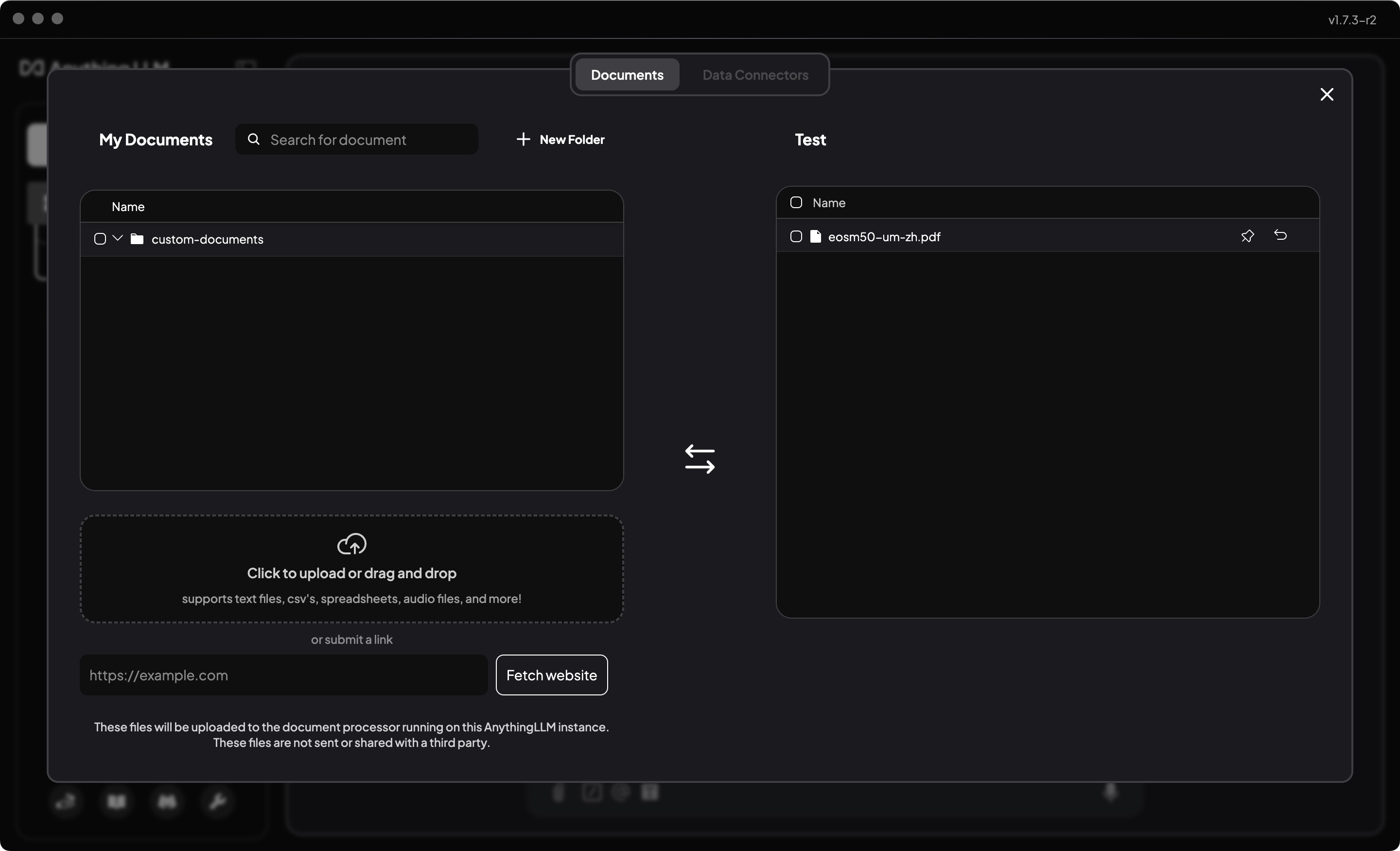
在投喂数据之前,我们先选择一份测试用的数据,支持PDF、Txt、Word、csv等格式。
- 点击工作空间的上传按钮
- 选择或拖拽文件上传
- 选择已上传的文件,并点击
Move to workspace添加到工作空间 - 再点击“Save and Embed”
- 然后就可以返回工作空间,对话了
新建线程可以直接点击提示的upload a document上传文件。
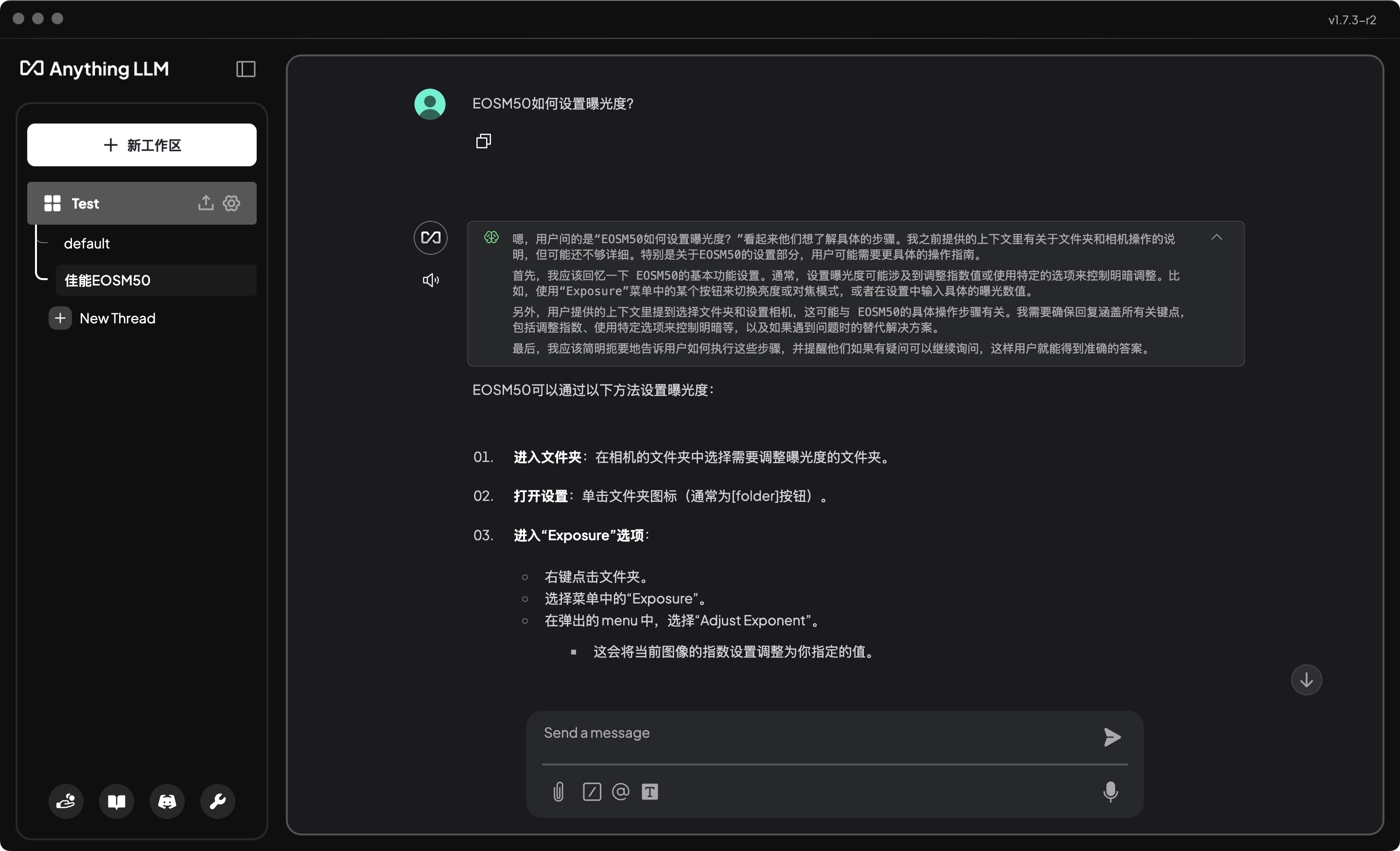
从回答的思考中,我们可以看到是引用了我们提供的上下文的。
注意 感觉1.5B的效果还是不行,后续可以尝试7B的模型。